This is an archived version of my home page. See the current version for more recent information.
Alternatively, have a look at my articles on web development for some really old things.
This is an archived version of my home page. See the current version for more recent information.
Alternatively, have a look at my articles on web development for some really old things.
Gijs van Tulder and Marleen de Bruijne
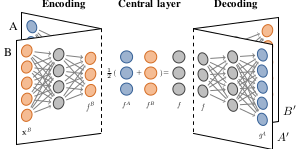
Machine learning algorithms can have difficulties adapting to data from different sources, for example from different imaging modalities. We present and analyze three techniques for unsupervised cross-modality feature learning, using a shared autoencoder-like convolutional network that learns a common representation from multi-modal data. We investigate a form of feature normalization, a learning objective that minimizes crossmodality differences, and modality dropout, in which the network is trained with varying subsets of modalities. We measure the same-modality and cross-modality classification accuracies and explore whether the models learn modality-specific or shared features. This paper presents experiments on two public datasets, with knee images from two MRI modalities, provided by the Osteoarthritis Initiative, and brain tumor segmentation on four MRI modalities from the BRATS challenge. All three approaches improved the cross-modality classification accuracy, with modality dropout and per-feature normalization giving the largest improvement. We observed that the networks tend to learn a combination of cross-modality and modality-specific features. Overall, a combination of all three methods produced the most cross-modality features and the highest cross-modality classification accuracy, while maintaining most of the samemodality accuracy.
Gijs van Tulder and Marleen de Bruijne
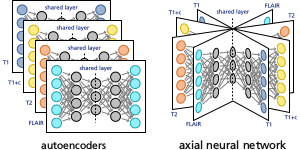
We used autoencoders and axial neural networks
to learn cross-modality representations
Differences in scanning parameters or modalities can complicate image analysis based on supervised classification. This paper presents two representation learning approaches, based on autoencoders, that address this problem by learning representations that are similar across domains. Both approaches use, next to the data representation objective, a similarity objective to minimise the difference between representations of corresponding patches from each domain. We evaluated the methods in transfer learning experiments on multi-modal brain MRI data and on synthetic data. After transforming training and test data from different modalities to the common representations learned by our methods, we trained classifiers for each of pair of modalities. We found that adding the similarity term to the standard objective can produce representations that are more similar and can give a higher accuracy in these cross-modality classification experiments.
Gijs van Tulder and Marleen de Bruijne
The choice of features greatly influences the performance of a tissue classification system. Despite this, many systems are built with standard, predefined filter banks that are not optimized for that particular application. Representation learning methods such as restricted Boltzmann machines may outperform these standard filter banks because they learn a feature description directly from the training data. Like many other representation learning methods, restricted Boltzmann machines are unsupervised and are trained with a generative learning objective; this allows them to learn representations from unlabeled data, but does not necessarily produce features that are optimal for classification. In this paper we propose the convolutional classification restricted Boltzmann machine, which combines a generative and a discriminative learning objective. This allows it to learn filters that are good both for describing the training data and for classification. We present experiments with feature learning for lung texture classification and airway detection in CT images. In both applications, a combination of learning objectives outperformed purely discriminative or generative learning, increasing, for instance, the lung tissue classification accuracy by 1 to 8 percentage points. This shows that discriminative learning can help an otherwise unsupervised feature learner to learn filters that are optimized for classification.
Gijs van Tulder and Marleen de Bruijne
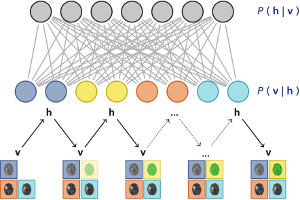
Restricted Boltzmann machines can be used to
predict a missing sequence given the others
The classification and registration of incomplete multi-modal medical images, such as multi-sequence MRI with missing sequences, can sometimes be improved by replacing the missing modalities with synthetic data. This may seem counter-intuitive: synthetic data is derived from data that is already available, so it does not add new information. Why can it still improve performance? In this paper we discuss possible explanations. If the synthesis model is more flexible than the classifier, the synthesis model can provide features that the classifier could not have extracted from the original data. In addition, using synthetic information to complete incomplete samples increases the size of the training set.
We present experiments with two classifiers, linear support vector machines (SVMs) and random forests, together with two synthesis methods that can replace missing data in an image classification problem: neural networks and restricted Boltzmann machines (RBMs). We used data from the BRATS 2013 brain tumor segmentation challenge, which includes multi-modal MRI scans with T1, T1 post-contrast, T2 and FLAIR sequences. The linear SVMs appear to benefit from the complex transformations offered by the synthesis models, whereas the random forests mostly benefit from having more training data. Training on the hidden representation from the RBM brought the accuracy of the linear SVMs close to that of random forests.
Gijs van Tulder and Marleen de Bruijne

Filters learned from lung tissue data
Performance of automated tissue classification in medical imaging depends on the choice of descriptive features. In this paper, we show how restricted Boltzmann machines (RBMs) can be used to learn features that are especially suited for texture-based tissue classification. We introduce the convolutional classification RBM, a combination of the existing convolutional RBM and classification RBM, and use it for discriminative feature learning. We evaluate the classification accuracy of convolutional and non-convolutional classification RBMs on two lung CT problems. We find that RBM-learned features outperform conventional RBM-based feature learning, which is unsupervised and uses only a generative learning objective, as well as often-used filter banks. We show that a mixture of generative and discriminative learning can produce filters that give a higher classification accuracy.
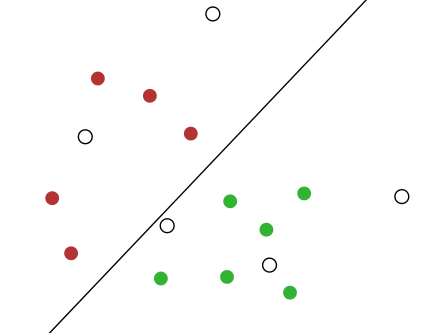
Which example should we label next?
Active learning sounds like a wonderful idea: select the most interesting examples to learn the best classifier with the least effort. Not every example is equally helpful for training your classifier. If labelling examples is expensive, it makes sense to label only those examples that you expect will give a large improvement to your classifier.
Unfortunately, using a non-random and unrepresentative selection of samples violates the basic rules of machine learning. It is therefore not surprising that active learning can sometimes lead to poor results because its unnatural sample selection produces the wrong classifier.
Modern active learning algorithms try to avoid these problems and can be reasonably successful at it. One of the remaining problems is that of sample reusability: if you used active learning to select a dataset tailored for one type of classifier, can you also use that same dataset to train another type of classifier?
In my thesis I investigate the reusability of samples selected by the importance-weighted active learning algorithm, one of the current state-of-the-art active learning algorithms. I conclude that importance-weighted active learning does not solve the sample reusability problem completely. There are datasets and classifiers where it does not work.
In fact, as I argue in the second part of my thesis, I think it is impossible to have an active learning algorithm that can always guarantee sample reusability between every pair of classifiers. To specialise your dataset for one classifier, you must necessarily exclude samples that could be useful for others. If you want to do active learning, decide what classifier you want to use before you start selecting your samples.

A simple educational game.
A fellow student and I built this game as part of a course on educational software. Intended for high-school students, it lets you explore mathematical formulas and their corresponding graphs. Balls enter the screen and tumble down the graphs that you have placed there. By choosing the right formulas to build your graphs, you guide the balls from the entrance to the exit.
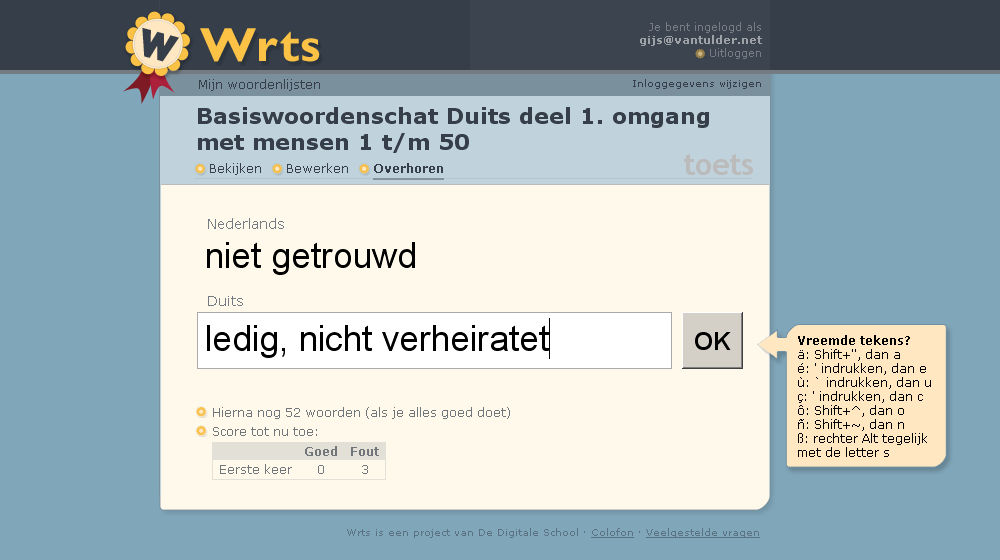
Online vocabulary training tool.
Wrts helps you to learn a foreign language: enter the words you want to learn and let the computer test you. Although not a very original idea – there are many tools like this – the easy-to-use (and free) Wrts quickly became quite successful among Dutch high school students. At the start of 2010 the site had over 1 million accounts.
The text-to-speech function helps students to learn not just the spelling but also the pronunciation of the words.
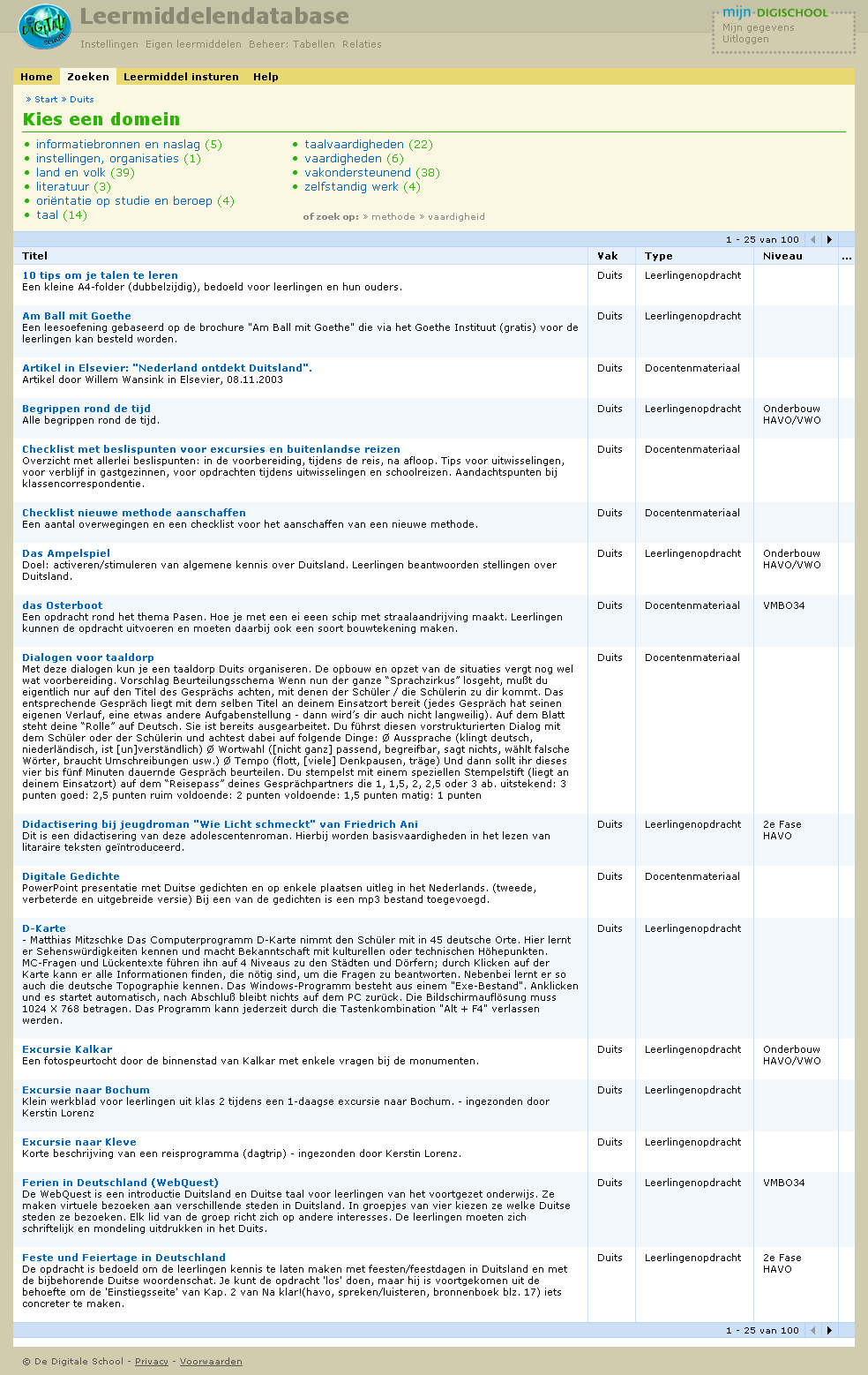
Learning materials exchange site for Dutch primary and secondary education.
De Digitale School, a Dutch foundation, operates a number of free communities for Dutch and Belgian teachers. The leermiddelendatabase allows these teachers to share and exchange their lesson ideas and materials.
When uploading their learning objects, teachers provide metadata that describes the contents of the lesson. The learning objects and metadata are also exchanged via EduStandaard, the Dutch education metadata initiative.
The leermiddelendatabse is in Dutch.
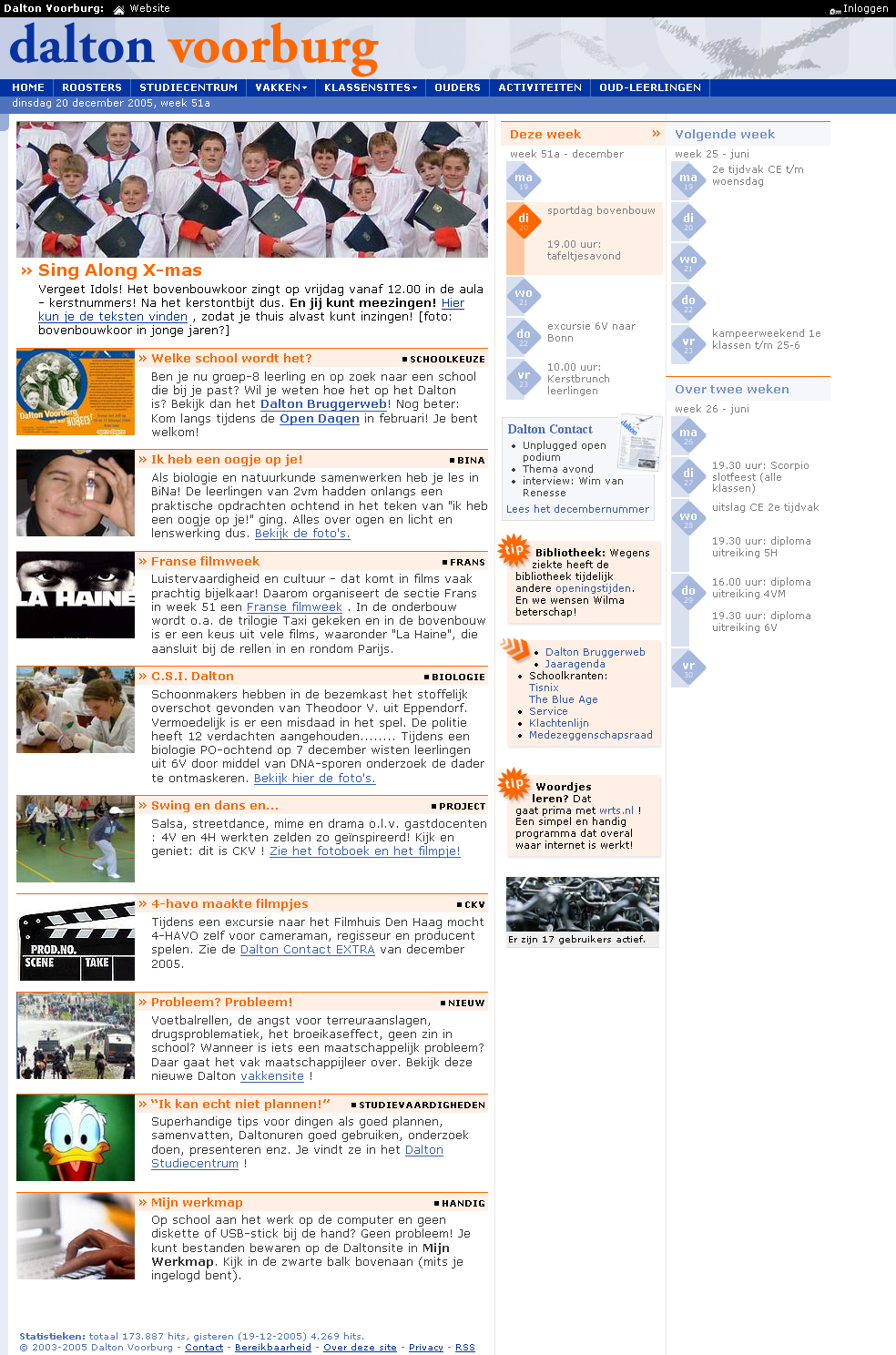
School website with cms and other applications.
Starting in 2002, I built and maintained a content management system for the website of my former high school. With a few modifications the system is still in use (as of 2013). The content management system makes it easy for teachers to upload and maintain their own course pages.
Besides the main website I built several smaller web-based tools.
The website is in Dutch.
Babak Loni, Gijs van Tulder, Pascal Wiggers, David M.J. Tax, Marco Loog
For a course project on ‘Real-Time AI and Automated Speech Recognition’ at the Delft University of Technology, Babak Loni and I did some work on question classification. Babak further developed and published a question classification library that started from this project.
For the final project of my Bachelor of Science in Computer Science I did an internship at Greetinq in Delft. During three months, Roland Heinrichs and I developed a web-based prototype for an iPhone interface to their personalised voicemail service.